Introduction
List crawling has transformed how businesses, marketers, and researchers collect data online. From real estate listings in Memphis and Dallas to dating boards and e-commerce marketplaces, automated tools now extract structured information in minutes — something humans could take weeks to do.
Thank you for reading this post, don’t forget to subscribe!At its core, list crawling is the process of scanning category or listing pages, extracting relevant data, and compiling it into usable formats like CSV, Excel, or JSON. Today, you’ll learn everything: how a list crawler works, ethical considerations, city-based crawlers like list crawler Houston, ATL list crawler, and crawler list Baltimore, the best tools, Python-based DIY methods, and FAQs to guide your journey.
What Is List Crawling?
List crawling is an automated process of scanning structured web pages to extract data like:
-
Titles and descriptions
-
Prices and rates
-
Contact information (phone/email)
-
URLs and links
-
Ratings and reviews
Unlike regular web crawling, which indexes general site content, list crawling focuses on listings and directories, making it ideal for lead generation, market research, competitor analysis, and trend monitoring.
How a List Crawler Works (Step-by-Step)
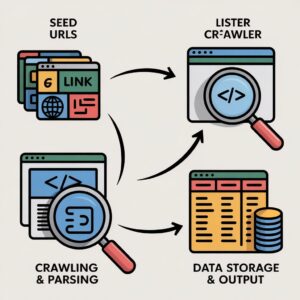
Stage 1 – Target Identification & Seed URLs
The crawler starts with predefined “seed” URLs — these are the pages containing the lists you want to extract, such as:
-
Craigslist apartments in Memphis
-
Real estate listings in Atlanta
-
E-commerce category pages
Stage 2 – Crawling & Parsing
The crawler fetches the HTML, parses the page structure, identifies items (titles, prices, links), and automatically navigates pagination to continue extraction.
Stage 3 – Data Storage & Output
Cleaned, deduplicated data is exported to:
-
CSV / Excel
-
Google Sheets
-
JSON / APIs
List Crawling Pipeline
| Stage | Action | Analogy |
|---|---|---|
| Seeding | Provide starting URLs | Giving a taxi an address |
| Crawling | Download HTML | Taxi driving to the address |
| Parsing | Extract data points | Reading street signs |
| Storing | Save structured file | Writing addresses in a notebook |
Why List Crawling Is Important in 2025
-
Real Estate: Crawl list crawler Memphis or list crawling Atlanta for rental trends and investment opportunities.
-
E-commerce: Track 50,000+ products across Shopify, Amazon, eBay.
-
Recruitment: Scrape job boards like Indeed & LinkedIn efficiently.
-
Dating Research: Analyze public profiles (list crawling dating) for academic or market studies.
-
Local Lead Generation: Find service requests via list crawling Louisville KY or list crawler Cleveland.
Types of List Crawlers
1. DIY Python Crawlers
-
Libraries: BeautifulSoup, Scrapy, Selenium
-
Highly customizable for developers
-
Requires coding and infrastructure knowledge
Python Example:
2. No-Code Platforms
-
Tools: ParseHub, Octoparse, Apify
-
Easy setup, minimal coding
-
Managed proxy & anti-block systems
3. Commercial/Niche Crawlers
-
Targeted for cities like Houston, Tampa, Baltimore
-
Fast, ready-made, but expensive
-
Higher ethical/legal risk
Best List Crawler Tools & Platforms (2025)
| Tool | Best For | Notes |
|---|---|---|
| Bright Data | Large-scale enterprise | Residential + ISP proxies |
| Apify Actors | Flexibility | No-code + full-code |
| Scrapy Cloud | Developers | Python-focused |
| Octoparse | Beginners | Point & click |
| ParseHub | Medium users | Free tier available |
| WebScraper.io | Small jobs | Chrome extension |
| Zyte | Enterprise | AI-driven extraction |
| Diffbot | Automated AI | Structured data focus |
| Scrape.it | Anti-block | Built-in unblocking |
| Listly.io | CSV scraping | Excel-style |
| Simplescraper.io | Quick CSV | One-click |
| Hexomatic | Automation combo | No-code + scraping |
| Bardeen.ai | AI agent crawler | Train robots in minutes |
| Browse AI | Quick setup | Low learning curve |
| Crawlbase | JS-heavy sites | Former ProxyCrawl |
| ScraperAPI | Simple API | Rotating proxies included |
| ZenRows | All-in-one | Headless browser |
Best Proxies for List Crawling
| Provider | Type | Success Rate | Price per GB |
|---|---|---|---|
| Bright Data | Residential + ISP | 99.2% | $8.50–$15 |
| Smartproxy | Residential | 98.7% | $7–$10 |
| Oxylabs | Datacenter + Residential | 98.4% | $10–$17 |
| SOAX | Mobile + Residential | 97.9% | $6.60–$11 |
| NetNut | ISP proxies | 99.1% | $12–$20 |
Legal, Ethical, and Risk Considerations
-
Respect robots.txt
-
Avoid personal/private data
-
Rate-limit requests
-
Don’t bypass security
Legality Table:
| Practice | Likely Legality | Risk |
|---|---|---|
| Public factual data | Legal | Low |
| Using official API | Legal | Low |
| Violating ToS for personal use | Grey | Civil lawsuits, IP ban |
| Circumventing access for commercial use | Likely Illegal | CFAA violation, lawsuits |
| Scraping dating profiles | Illegal | Criminal charges |
Pros & Cons of List Crawling
Pros
-
Extract data 100× faster
-
Generate warm leads
-
Monitor trends instantly
-
Automate competitor research
-
Scale research efficiently
Cons
-
Risk of being blocked or banned
-
Requires proxies & anti-bot tech
-
Legal gray areas
-
Messy/stale data possible
-
Technical maintenance needed
Alternatives to Aggressive Crawling
-
Official APIs → Structured, legal
-
Data Partnerships → Direct licensing
-
Manual/Hybrid → Low-volume research
Actionable Tips for Effective List Crawling
-
Respect robots.txt
-
Limit request rate (3–10 seconds delay)
-
Use rotating proxies
-
Identify your bot with proper User-Agent
-
Only scrape needed data
-
Review Terms of Service
City-Specific List Crawling Use Cases
| City | Use Case |
|---|---|
| Memphis | Real estate, rental trends |
| Atlanta | Market leads, dating boards |
| Dallas | Business listings |
| Houston | E-commerce tracking |
| Tampa | Local service leads |
| Cleveland | Classified ad aggregation |
| Louisville KY | Handyman / service requests |
| Baltimore | Competitive analysis |
Frequently Asked Questions
-
What is list crawling?
-
Is it legal?
-
Difference between list crawler & web crawler?
-
How fast can it crawl?
-
What is list crawling dating?
-
Risks of city-specific crawlers?
-
Can I sell crawled data?
-
Best tools for beginners?
-
Python vs no-code?
-
How to avoid bans?
-
Data accuracy issues?
-
Future of list crawling (AI/ethics)?
Conclusion: Master List Crawling Safely & Effectively
List crawling is a powerful tool, but ethical, legal, and technical considerations are key. Start small, focus on public data, respect ToS, and scale gradually using Python + proxies or no-code tools. City-specific crawlers like Memphis, Atlanta, Dallas, Houston, Tampa can give you an edge in real estate, e-commerce, and lead generation.
💡 Actionable Advice:
-
Define your data needs
-
Audit legality & ethics
-
Choose the right tool (DIY, no-code, or commercial)
-
Respect limits & transparency
-
Clean and verify your data
Follow this guide, and you’ll turn list crawling into a high-value, data-driven asset for your business, research, or market analysis in 2025.